
1)冲突是如何产生的?
上文中谈到,哈希函数是指如何对关键字进行编址的规则,这里的关键字的范围很广,可视为无限集,如何保证无限集的原数据在编址的时候不会出现重复呢?规则本身无法实现这个目的。举一个例子,仍然用班级同学做比喻,现有如下同学数据
张三,李四,王五,赵刚,吴露.....
假如我们编址规则为取姓氏中姓的开头字母在字母表的相对位置作为地址,则会产生如下的哈希表
| 位置 | 字母 | 姓名 | |
| 0 | a | ||
| 1 | b | ||
| 2 | c |
...
| 10 | L | 李四 |
...
| 22 | W | 王五,吴露 |
..
| 25 | Z | 张三,赵刚 |
我们注意到,灰色背景标示的两行里面,关键字王五,吴露被编到了同一个位置,关键字张三,赵刚也被编到了同一个位置。老师再拿号来找张三,座位上有两个人,"你们俩谁是张三?"
2)如何解决冲突问题
既然不能避免冲突,那么如何解决冲突呢,显然需要附加的步骤。通过这些步骤,以制定更多的规则来管理关键字集合,通常的办法有:
a)开放地址法
这个方法的基本思想是:当发生地址冲突时,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止。这个过程可用下式描述:
H i ( key ) = ( H ( key )+ d i ) mod m ( i = 1,2,…… , k ( k ≤ m – 1))
其中: H ( key ) 为关键字 key 的直接哈希地址, m 为哈希表的长度, di 为每次再探测时的地址增量。
采用这种方法时,首先计算出元素的直接哈希地址 H ( key ) ,如果该存储单元已被其他元素占用,则继续查看地址为 H ( key ) + d 2 的存储单元,如此重复直至找到某个存储单元为空时,将关键字为 key 的数据元素存放到该单元。
增量 d 可以有不同的取法,并根据其取法有不同的称呼:
( 1 ) d i = 1 , 2 , 3 , …… 线性探测再散列;
( 2 ) d i = 1^2 ,- 1^2 , 2^2 ,- 2^2 , k^2, -k^2…… 二次探测再散列;
( 3 ) d i = 伪随机序列 伪随机再散列;
例1设有哈希函数 H ( key ) = key mod 7 ,哈希表的地址空间为 0 ~ 6 ,对关键字序列( 32 , 13 , 49 , 55 , 22 , 38 , 21 )按线性探测再散列和二次探测再散列的方法分别构造哈希表。
解:
( 1 )线性探测再散列:
32 % 7 = 4 ; 13 % 7 = 6 ; 49 % 7 = 0 ;
55 % 7 = 6 发生冲突,下一个存储地址( 6 + 1 )% 7 = 0 ,仍然发生冲突,再下一个存储地址:( 6 + 2 )% 7 = 1 未发生冲突,可以存入。
22 % 7 = 1 发生冲突,下一个存储地址是:( 1 + 1 )% 7 = 2 未发生冲突;
38 % 7 = 3 ;
21 % 7 = 0 发生冲突,按照上面方法继续探测直至空间 5 ,不发生冲突,所得到的哈希表对应存储位置:
下标: 0 1 2 3 4 5 6
49 55 22 38 32 21 13
( 2 )二次探测再散列:
下标: 0 1 2 3 4 5 6
49 22 21 38 32 55 13
注意:对于利用开放地址法处理冲突所产生的哈希表中删除一个元素时需要谨慎,不能直接地删除,因为这样将会截断其他具有相同哈希地址的元素的查找地址,所以,通常采用设定一个特殊的标志以示该元素已被删除。
b)再哈希法
当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。
比如上面第一次按照姓首字母进行哈希,如果产生冲突可以按照姓字母首字母第二位进行哈希,再冲突,第三位,直到不冲突为止
c)链地址法
将所有关键字为同义词的记录存储在同一线性链表中。如下: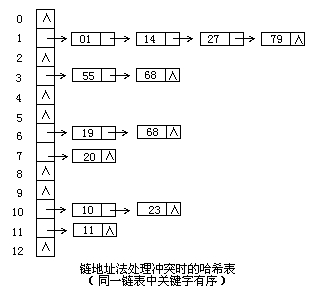
因此这种方法,可以近似的认为是筒子里面套筒子
d.建立一个公共溢出区
假设哈希函数的值域为[0,m-1],则设向量HashTable[0..m-1]为基本表,另外设立存储空间向量OverTable[0..v]用以存储发生冲突的记录。
经过以上方法,基本可以解决掉hash算法冲突的问题。
注:之所以会简单得介绍了hash,是为了更好的学习lzw算法,学习lzw算法是为了更好的研究gif文件结构,最后,我将详细的阐述一下gif文件是如何构成的,如何高效操作此种类型文件。



相关推荐
链地址法解决Hash冲突 很有用的,下载了试试吧,或许对你有用
C++实现的hash冲突解决算法,有好几种解决方法
NULL 博文链接:https://eleopard.iteye.com/blog/1766890
HASH冲突的介绍和几种解决方案,用例子来讲述冲突的处理方式。
Hash冲突的一般解决方案与字符串查找中hash的使用.docx
上篇文章 为什么哈希存取比较快?使用它需要付出什么代价 只是简单介绍了使用hash所带来的利与弊。并未涉及hash的技术细节,本文则着重学习一下如何解决哈希编址的冲突问题。
哈希表 相关概念、hash函数、hash冲突解决方案、代码示例
主要介绍了java开放地址法和链地址法解决hash冲突的方法示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
用线性探测法解决Hash冲突。设Hash函数为:Hash(Key)=[(Key的首字母序号)*100+(Key的尾字母序号)] Mod 41。关键字39个,参考C语言教材。 二、数据结构设计 ①关键字表的存储结构;②Hash表中的结点结构。频度、冲突...
基于codeblocks wxwidgets 的Marvell mac hash冲突计算小工具及源码
表头插入,使用链地址法处理冲突的哈希查找算法
官方网站:https://github.com/aappleby/smhasherMurmurHash算法,自称超级快的hash算法,是FNV的4-5倍。官方数据如下: OneAtATime – 354.163715 mb/sec FNV – 443.668038 mb/sec SuperFastHash – 985.335173 ...
这可以防止 DOS 攻击,其中攻击者发送大量哈希冲突的项目,这些项目被用作哈希映射中的键。 这也避免了通过从一个映射读取并写入另一个映射来意外的二次行为。 目标和非目标 AHash的输出没有固定的标准。这允许它...
(2)从键盘读入待查找的权重数值,以除留余数法为哈希函数,二次探测再散列法解决冲突建立哈希表,基于哈希算法从数组中查找相应的记录,计算相应的查找时间,并在屏幕上输出显示。(提示:当前计算机时间 函数 C\...
NULL 博文链接:https://128kj.iteye.com/blog/1683641
比如我们注入出数据库的hash,但是没办法拿到webshell 我们可以使用mysql_hash,用hash登陆并控制数据库 使用方法: mysql_hash.exe -u root -p Enter password: ***************************************** 其中1....
217种hashcat-V3.0所支持的哈希 举例,如md4、md5、sha1、sha256,部分特殊哈希的例子有官网说明的链接。
geohash解决计算附近距离,搜索附近的商业点,两个经纬度距离,地理位置应用处理
解决RFID隐私问题的一种新方法——Key值更新随机读取控制Hash锁.pdf